對影片處理而言,有一個非常關鍵的步驟,稱為 shot segmentation。將一長串的影片分割成 scene 和shot,如下圖所示。
Scene vs. Shot
- Scene:是表現情節的基本單位,每一個 scene 可能都在講述不同的劇情或故事,一個 scene 中會有很多個 shots
- Shot:同一個 scene 中的不同畫面,可能是不同人物之間的切轉
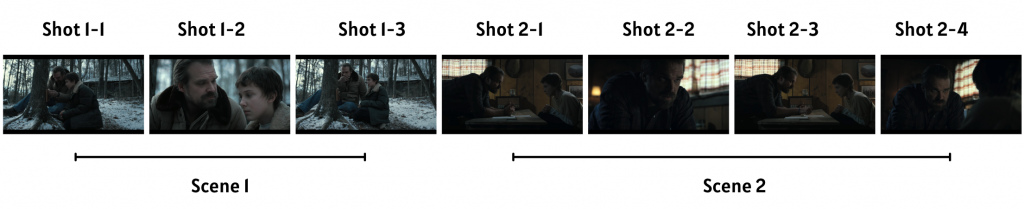
圖片來源:Stranger Things
為了之後的模型訓練或是其他應用,Netflix 需要先將影片切割成 shot。除了人為剪輯以外,他們當然也希望能夠訓練模型,自動偵測影片內容中的場景變化,有助於他們前處理影片。
Netflix 想要偵測 scenes 之間的轉換的任務被稱為 scene boundary detection,他們主要使用兩種方法來偵測影音內容中的場景變化:
讓我們來一一介紹吧!
第一個方法的概念很直觀,利用劇本的資訊來分割影片。劇本就如同電影或節目的設計圖,以特定格式編寫,每個場景都會以場景標題為開頭,顯示拍攝地點和時間等資訊。這種統一的格式有助於 Netflix 將劇本解析成結構化格式,再按照這份資料切分畫面。
不過,這個方法並非想像中容易,因為劇本是事前編寫的,無法反映出拍攝過程中即興做出的變動,或是後期製作和剪輯的結果,劇本不會因為這些變動而被改寫。
為了處理這種有雜訊而不一致的資料來源,Netflix 需要先將「帶有時間戳記的文字」(如字幕和口語說明)與「劇本文字」(對白和動作描述)相互對齊。這個對齊的過程有兩個主要挑戰:
為了應對這些挑戰,Netflix 分別使用以下方法:
為了處理即興的文字變動,他們使用 pre-trained 的 sentence-level embeddings 來表示兩個來源中的文字,以找到相似語意的對白。
第二個問題的解決辦法是使用 dynamic time warping (DTW),這是一種用於測量兩個在時間或速度上有所不同的序列的相似性方法。
Netflix 會使用 DTW 將劇本文字(對白和動作描述)與帶有時間戳記的文字(如字幕和口語描述)進行比對,藉此,絕大多數的重要事件都能夠很好地被對齊。並且,因為這些劇本文字是帶有時間戳記的,可以用來表現影片中可能的場景邊界。
結果如下圖所示,他們可以根據劇本文字找到相對應的影片片段,成功地分割影片:

圖片來源:[1]
雖然上述的方法已經可以達到 Netflix 想要的成果,但是他們並非總是能夠得到高品質的劇本資訊。因此,他們決定訓練一個序列模型,直接預測每個場景轉換的時間點。
Netflix 使用的模型架構相對簡單——就是一個雙向的 GRU(biGRU),會輸入一個 shot embedding,預測此 shot 是否為 scene 的結尾。
這個架構的價值不在於使用的模型本身,而是他們想要訓練的資料不容易取得(有被標記過的場景變化資料)。另外,如果要在大規模的資料上訓練這種 shot embeddings 也不容易。因此,他們決定使用一些已經 pre-trained 好的 embedding models。
接著,他們要將 video embeddings 和 audio embeddings 結合起來,他們嘗試兩種方法:
結果
最後來看看結果吧!他們跟現有的 SOTA 相比,跟目前的 baseline 結果相當,甚至超越。另外,他們發現新增 audio embeddings 可以將結果提升 10-15%。最後,他們發現 late fusion 的結果也會比 early fusion 還要進步 3-7%。
以上就是今天的內容啦!Netflix 使用兩種方法來偵測場景邊界,這些方法利用了各種可用的模態——劇本、音訊和影片,也得到非常優秀的效果,能夠自動偵測影片內容中的場景變化,有助於他們進行影片的前處理。
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
Reference
[1] https://netflixtechblog.com/detecting-scene-changes-in-audiovisual-content-77a61d3eaad6
[2] https://en.wikipedia.org/wiki/Dynamic_time_warping


 iThome鐵人賽
iThome鐵人賽